Is {fastDummies} any better than {stats} to create dummy variables? Let’s find out.
Author
Rahul
Published
December 16, 2020
tl;dr
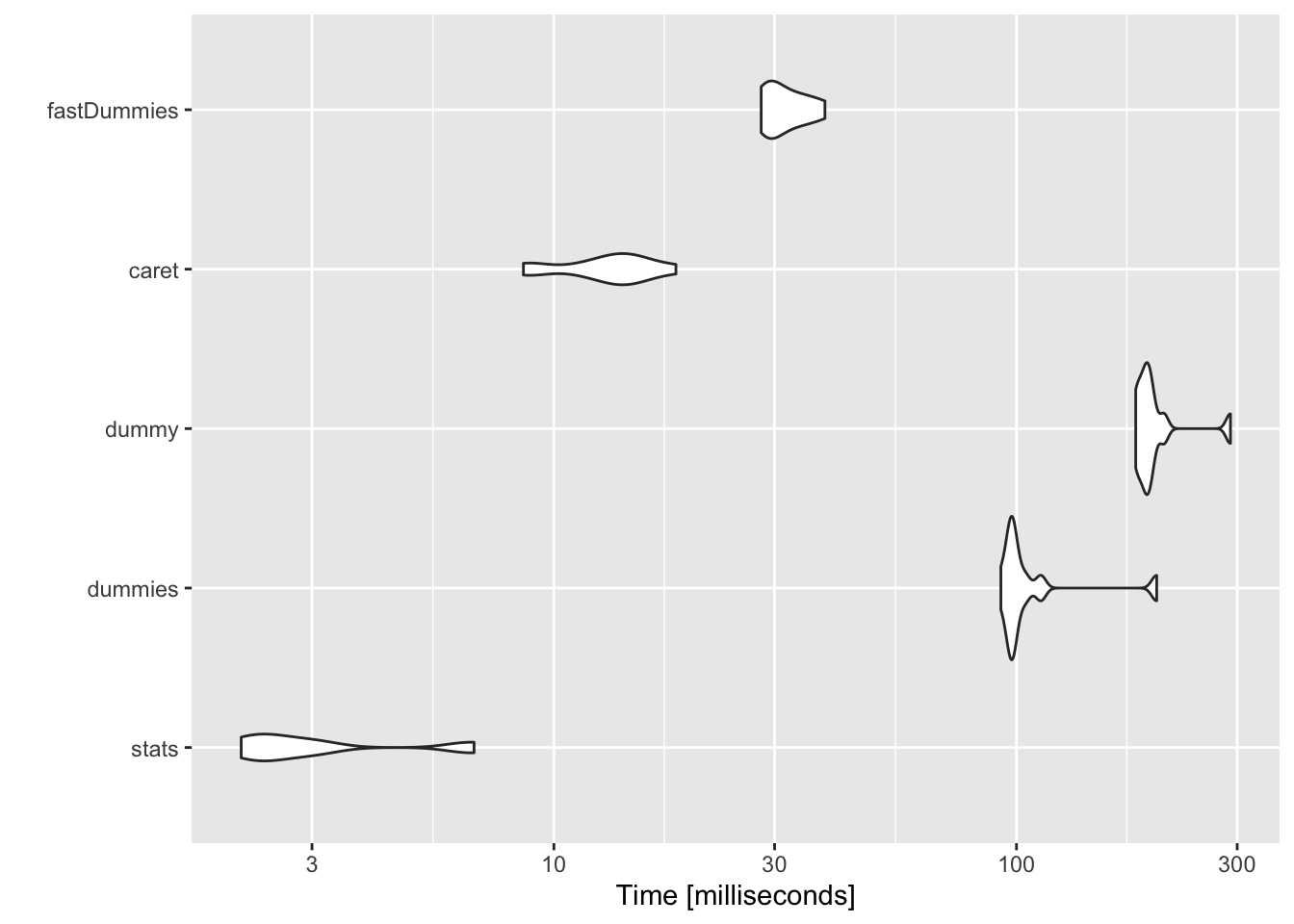
{stats} continues to dominate the speed tests
{fastDummies} had similar speeds only for dataframes with rows ~1M
{dummy} and {dummies} are the slowest
Motivation
In 2017, I compared the performance of four packages {stats}, {dummies}, {dummy} and {caret} to create dummy variables in this post.
Jacob Kaplan of UPenn has created a new package {fastdummies} which claims to be faster than other existing packages.
Let’s test it out.
Machine
I’m running these tests on a 2019 MacBook Pro running macOS Catalina (10.15.7) on a 2.4 GHz 8-Core Intel i9 with 32 MB 2400 MHz DDR4, in a docker container running:
platform x86_64-pc-linux-gnu
arch x86_64
os linux-gnu
system x86_64, linux-gnu
status
major 4
minor 0.0
year 2020
month 04
day 24
svn rev 78286
language R
version.string R version 4.0.0 (2020-04-24)
nickname Arbor Day
Interestingly, number of levels per factor have little/no impact on performance for stats, caret and dummies. fastDummies & dummies show a positive correlation to levels.