Performance Benchmarking for Dummy Variable Creation
Benchmarking
How do the four popular methods of creating dummy variables perform on large datasets? Let’s find out!
Author
Rahul
Published
September 27, 2017
Motivation
Very recently, at work, we got into a discussion about creation of dummy variables in R code. We were dealing with a fairly large dataset of roughly 500,000 observations for roughly 120 predictor variables. Almost all of them were categorical variables, many of them with a fairly large number of factor levels (think 20-100). The types of models we needed to investigate required creation of dummy variables (think xgboost). There are a few ways to convert categoricals into dummy variables in R. However, I did not find any comparison of performance for large datasets.
So here it goes.
Why do we need dummy variables?
I won’t say any more here. Plenty of good resources on the web: here, here, and here.
Ways to create dummy variables in R
These are the methods I’ve found to create dummy variables in R. I’ve explored each of these
stats::model.matrix()
dummies::dummy.data.frame()
dummy::dummy()
caret::dummyVars()
Prepping some data to try these out. Using the HairEyeColor dataset as an example. It consists of 3 categorical vars and 1 numerical var. Perfect to try things out. Adding a response variable Y too.
dummy creates dummy variables of all the factors and character vectors in a data frame. It also supports settings in which the user only wants to compute dummies for the categorical values that were present in another data set. This is especially useful in the context of predictive modeling, in which the new (test) data has more or other categories than the training data. 1
Some pros
Works with tibbles
Retains numerical columns as is
Can create based dummy variables for numeric columns too
p parameter can select terms in terms of frequency
Can grab only those variables in a separate dataframe
Can create based dummy variables for numeric columns too
Some cons
Doesn’t have a formula interface to specify what Y is. Need to manually remove response variable from dataframe
Lastly, there’s the caret package’s dummyVars(). This follows a different paradigm. First, we create reciepe of sorts, which just creates an object that specifies how the dataframe gets dummy-fied. Then, use the predict() to make the actual conversions.
Some pros
Works on creating full rank & less than full rank matrix post-conversion
Has a feature to keep only the level names in the final dummy columns
Can directly create a sparse matrix
Retains numerical columns as is
Some cons
Y needs a factor
If the cateogical variables aren’t factors, you can’t use the sep=' ' feature
I’ve run these benchmarks on my Macbook Pro with these specs:
Processor Name: Intel Core i5
Processor Speed: 2.4 GHz
Number of Processors: 1
Total Number of Cores: 2
L2 Cache (per Core): 256 KB
L3 Cache: 3 MB
Memory: 8 GB
Smaller datasets
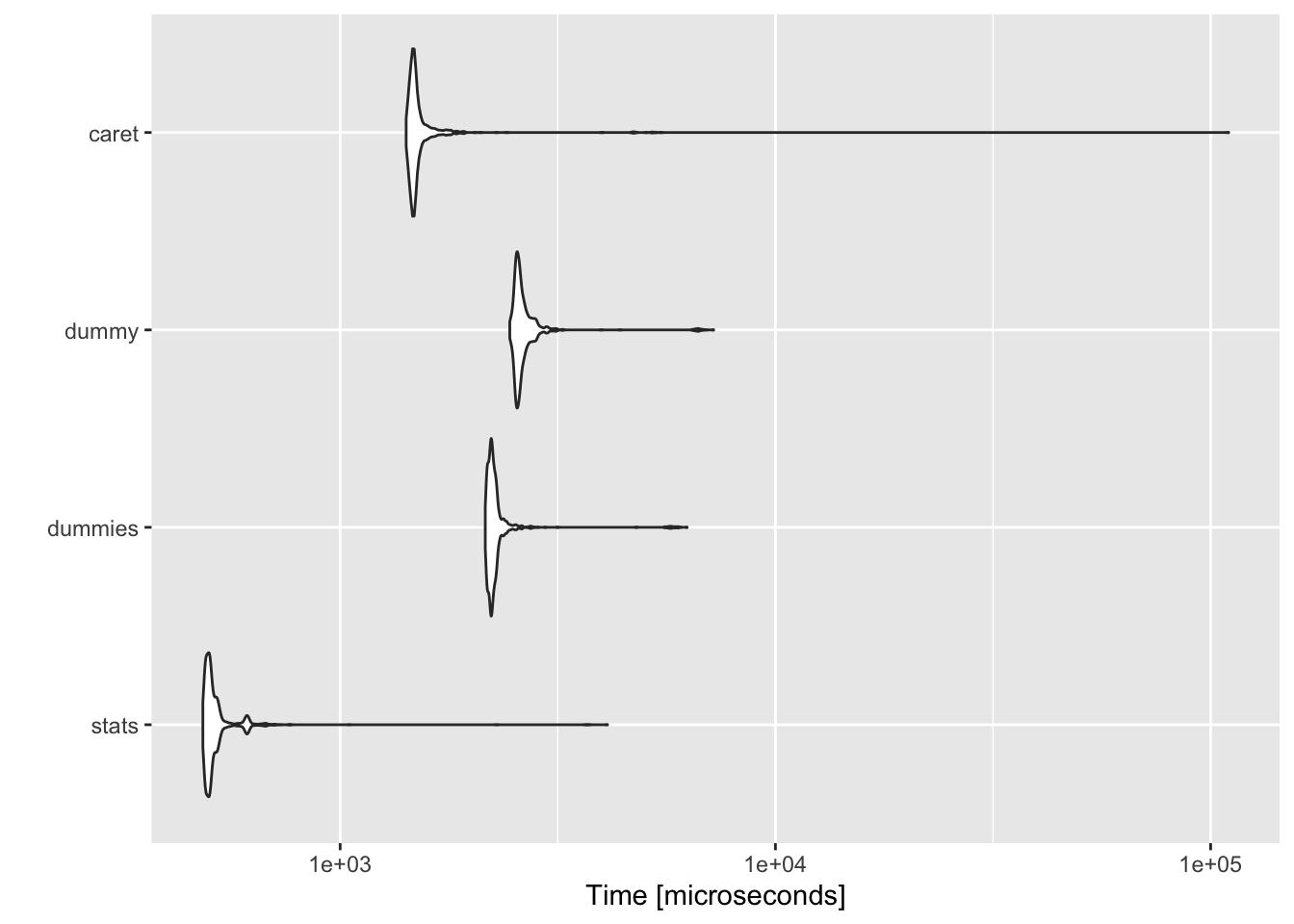
The first dataset used is the HairEyeColor. 32 rows, 1 numeric var, 3 categorical var. All the resulting dataframes are as similar as possible… they all retain the Y variable at the end.
The results speak for themself. The stats is clearly the fastest with dummies and caret being a more distant 2nd & 3rd.
Large datasets
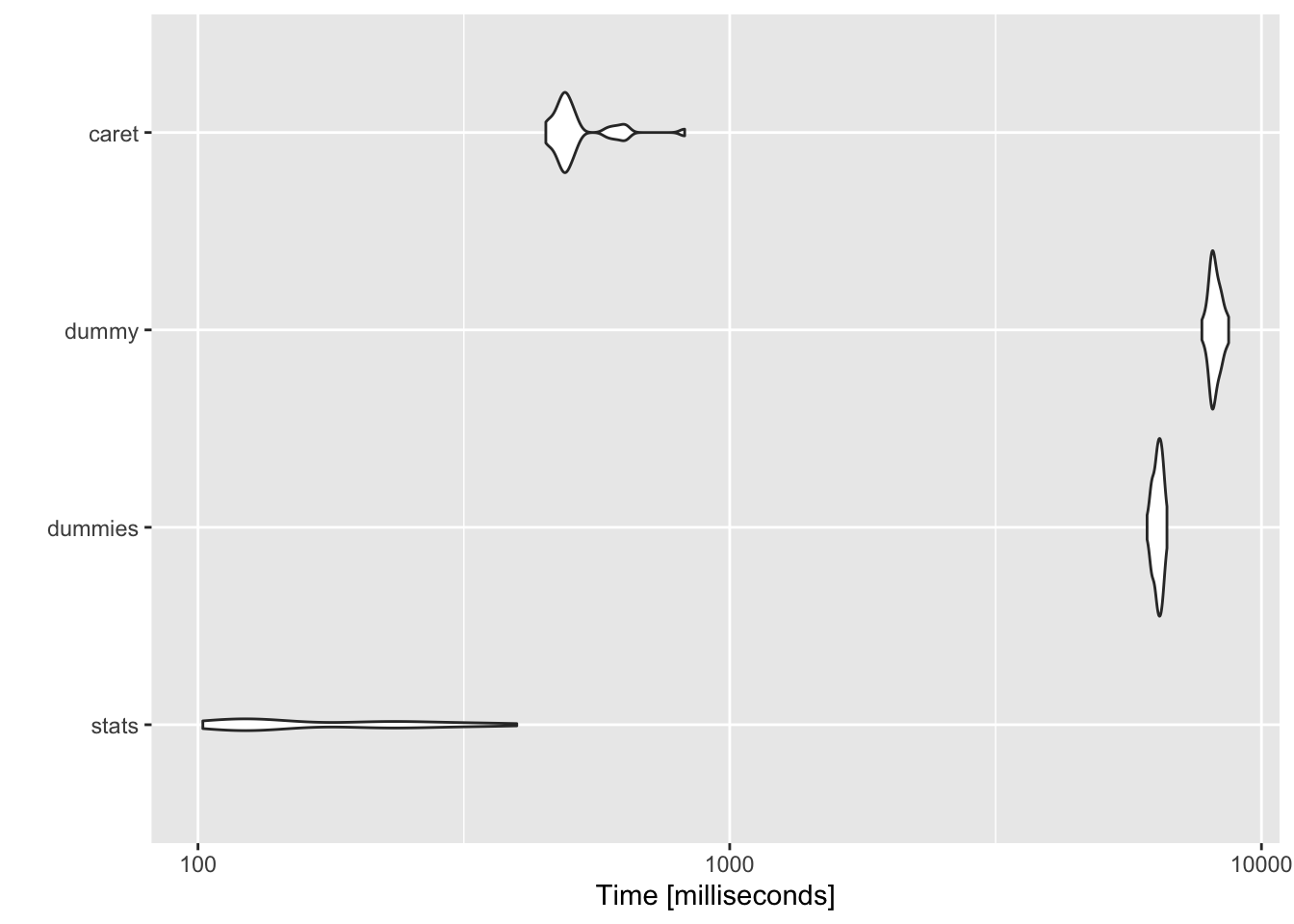
To leverage a large dataset for this analysis, I’m using the Accident & Traffic Flow dataset, which is fairly big - 570,011 rows and 33 columns. I’ve narrowed down to 7 categorical variables to test the packages, and I’ve created a fake response variable as well.